I built a self-hosted Kubernetes cluster on AWS EC2 to run ghibli transfomation app with inference on nvidia gpu. The whole setup is done using infrastructure-as-code using Terraformand Helm. In this post, I’ll share the architecture, challenges faced, and lessons learned throughout this journey.
Why Self-Host Kubernetes with GPU? Link to heading
Because I like pain and suffering ;-) In all seriousness, I wanted to see how hard can it be to build working k8s cluster on top of EC2 instances and run inference? It also has a few advantages:
- A ton of learning
- I don’t have any GPUs of my own so had to use some cloud :D
- Complete control over the cluster configuration
- Better understanding of AWS and Kubernetes internals
- I wanted something useful to do with Claude Code
Infrastructure Overview Link to heading
My cluster uses a minimalist but effective architecture:
- 1 Control Plane node (t3.medium) running essential Kubernetes services
- 1 Worker node with NVIDIA T4 GPU (g4dn.xlarge) for compute-intensive workloads
- Network Load Balancer for external access to the API and applications
Here’s a visual representation of how everything fits together:
┌──────────────────────┐
│ │
│ AWS Cloud Region │
│ │
└──────────────────────┘
│
▼
┌──────────────────────────────────────────────────────────┐
│ VPC 10.0.0.0/16 │
│ │
┌───────────────┴──────────────┐ ┌───────────────────────┐ │
│ │ │ │ │
┌─────────▼─────────┐ ┌───────────────▼──────────┐ │ │ │
│ │ │ │ │ │ │
│ Public Subnet │ │ Public Subnet │ │ │ │
│ 10.0.1.0/24 │ │ 10.0.2.0/24 │ │ │ │
│ │ │ │ │ ┌─────────────────┐ │ │
│ ┌───────────────┐ │ │ ┌──────────────────────┐ │ │ │ Network Load │ │ │
│ │ Control Plane │ │ │ │ Worker Node w/GPU │ │ │ │ Balancer │ │ │
│ │ t3.medium │ │ │ │ g4dn.xlarge │ │ │ └────────┬────────┘ │ │
│ │ │◄┼────┼─┼─────────────────────►│ │ │ │ │ │
│ │ kube-apiserver│ │ │ │ kubelet │ │ │ │ │ │
│ │ etcd │ │ │ │ NVIDIA GPU Driver │ │ │ │ │ │
│ │ scheduler │ │ │ │ containerd │ │ │ │ │ │
│ │ controller-mgr│ │ │ │ NVIDIA Runtime │ │ │ │ │ │
│ └───────────────┘ │ │ │ │ │ │ │ │ │
│ ▲ │ │ │ ┌──────────────────┐ │ │ │ │ │ │
│ │ │ │ │ │ Ingress NGINX │◄┼─┼──────┼────────────┘ │ │
│ │ │ │ │ │ Controller │ │ │ │ │ │
│ │ │ │ │ └──────────────────┘ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │
│ │ │ │ │ ┌──────────────────┐ │ │ │ │ │
│ └─────────┼────┼─┼►│ CoreDNS │ │ │ │ │ │
│ │ │ │ └──────────────────┘ │ │ │ │ │
│ │ │ │ │ │ │ │ │
│ │ │ │ ┌──────────────────┐ │ │ │ │ │
│ │ │ │ │ Calico │ │ │ │ │ │
│ │ │ │ └──────────────────┘ │ │ │ │ │
│ │ │ │ │ │ │ │ │
│ │ │ │ ┌──────────────────┐ │ │ │ │ │
│ │ │ │ │ Ghibli App (Pod) │ │ │ │ │ │
│ │ │ │ │ w/GPU Access │ │ │ │ │ │
│ │ │ │ └──────────────────┘ │ │ │ │ │
│ │ │ └──────────────────────┘ │ │ │ │
└───────────────────┘ └──────────────────────────┘ └───────────────────────┘ │
│ │
└───────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ │
│ Internet │
│ │
└─────────────────────────────────────────┘
Setting Up GPU Infrastructure Link to heading
Integrating GPU support into Kubernetes was one of the most challenging and interesting aspects of this project. Here’s how I approached it:
Hardware Selection Link to heading
For the worker node, I chose a g4dn.xlarge instance which provides:
- 4 vCPUs and 16GB RAM - enough for handling moderate workloads
- 1 NVIDIA T4 GPU with 16GB VRAM - enough for the simple infrerence need I had
- 2,560 CUDA cores and 320 Tensor cores
Software Stack Link to heading
Getting the GPU software stack right required careful version matching:
- NVIDIA Drivers (535.xx series)
- CUDA 12.1
- containerd with nvidia-container-runtime
- NVIDIA Device Plugin for Kubernetes integration
GPU Setup Process Link to heading
The worker node initialization process required several critical steps:
- Installing the correct NVIDIA drivers and libraries
- Configuring containerd to use the NVIDIA runtime
- Setting up the device plugin directory with proper permissions
- Creating the RuntimeClass for GPU workloads
Building a Ghibli-Style Image Transform Application Link to heading
To demonstrate the GPU capabilities, I built a PyTorch-based application that transforms regular photos into Ghibli-style animations.
Application Architecture Link to heading
The app follows a straightforward design:
- Frontend: Simple HTML/CSS/JS for image upload and display
- Backend: Flask application running the PyTorch model
- GPU Acceleration: CUDA-powered tensor operations
- Kubernetes Deployment: Pod with GPU resource requests
Request Flow Link to heading
When a user uploads an image, the request flows through:
- Network Load Balancer
- NGINX Ingress Controller
- Kubernetes Service
- Application Pod (with GPU access)
- Response with transformed image
Implementing TLS & Certificate Management Link to heading
Certificate Manager Setup Link to heading
I deployed cert-manager in the cluster with:
- ClusterIssuer configured for Let’s Encrypt production
- DNS01 validation using Cloudflare API for domain ownership verification
Certificate Lifecycle Link to heading
The automatic certificate process works as follows:
- Ingress resources request certificates via annotations
- cert-manager creates Certificate resources
- DNS validation occurs via Cloudflare
- Valid TLS certificates are stored as Kubernetes secrets
- Ingress controller uses these certificates to serve HTTPS
Optimizing Costs Link to heading
Sleep/Wake Functionality Link to heading
I implemented scripts to scale the cluster down when not in use:
-
Sleep Mode:
- Scales EC2 instances to 0
- Removes the Network Load Balancer
- Retains all Kubernetes state (etcd data)
-
Wake Mode:
- Restores instances to desired count
- Recreates the Network Load Balancer
Cost Breakdown Link to heading
| Component | Type | Monthly Cost |
|---|---|---|
| Control Plane | 1 x t3.medium | ~$30 |
| Worker Nodes | 1 x g4dn.xlarge | ~$38 (spot) |
| Network LB | - | ~$16.43 |
| EBS Storage | gp3 | ~$15 |
| Total | - | ~$99/month |
With sleep/wake functionality, I can reduce costs by a lot.
Implementing Monitoring Link to heading
I stood up a simple and most basic obserbability stack:
Kubernetes Dashboard Link to heading
The official Kubernetes Dashboard provides a visual interface for:
- Cluster resource visualization
- Deployment management
- Pod logs and exec access
- Resource utilization graphs
It’s secured with token-based authentication and accessed through kubectl proxy.
Prometheus and Grafana Link to heading
For metrics collection and visualization:
-
Prometheus collects metrics from:
- Kubernetes components
- Node resource utilization
- Container metrics
- GPU statistics (utilization, memory, temperature)
-
Grafana provides dashboards for:
- Cluster overview
- Node resource utilization
- Pod resource consumption
- GPU performance metrics
Automated Port Forwarding Link to heading
To simplify access to monitoring services, I implemented a background port forwarding system that:
- Manages service connections
- Provides automatic token retrieval
- Tracks running port forwards
- Offers a unified interface for starting/stopping
Configuration Management Approach Link to heading
Managing the configuration of such a complex system required a layered approach:
Terraform for Infrastructure Link to heading
I used Terraform to manage all AWS infrastructure:
- VPC, subnets, security groups
- EC2 instances via Auto Scaling Groups
- Network Load Balancer configuration
- IAM roles and policies
Terraform gave me declarative configuration, state tracking, and incremental changes capability.
Helm for Kubernetes Applications Link to heading
For complex Kubernetes applications, Helm charts were essential:
- Monitoring stack (Prometheus, Grafana)
- NGINX ingress controller
- cert-manager
Helm simplified version management and configuration of these multi-resource applications.
Shell Scripts as Orchestration Layer Link to heading
Shell scripts served as the orchestration layer:
- Component installation
- Cluster sleep/wake functionality
- Monitoring setup
- Automated port forwarding
They integrate outputs from different tools and provide error handling for operational reliability.
Kubernetes Manifests for Applications Link to heading
For application-specific configuration, direct Kubernetes manifests provided:
- Precise control over resources
- Clarity for simpler deployments
- Version control alongside application code
Makefile as User Interface Link to heading
A Makefile ties everything together with a unified command interface, hiding implementation details while ensuring correct execution order.
Challenges and Lessons Learned Link to heading
GPU Support Complexity Link to heading
Integrating NVIDIA GPUs with Kubernetes was challenging due to:
- Version Compatibility: Finding compatible versions of NVIDIA drivers, CUDA, and Kubernetes components
- Driver Installation: Ubuntu 22.04 required specific libraries not in default repositories
- Runtime Configuration: Configuring containerd with NVIDIA runtime support
- Kernel Modules: Ensuring NVIDIA modules loaded properly at boot
I solved these by creating a comprehensive worker node initialization script that installed exact versions, configured the runtime properly, and verified GPU visibility.
Networking Challenges Link to heading
My initial Flannel CNI implementation faced several issues:
- Pod Communication Problems: Inconsistent connectivity between pods
- DNS Resolution Failures: CoreDNS pods with connectivity issues
- Service Accessibility: Unreachable ClusterIP services
- Network Policy Limitations: Inadequate security controls
Migrating to Calico CNI resolved these issues with more reliable networking, better diagnostics, robust network policies, and improved performance.
Future Plans Link to heading
While the current setup works well, I’m planning several improvements:
- Enhanced Security: Implementing more comprehensive security practices
- Horizontal Pod Autoscaling: Dynamic scaling based on GPU utilization
- CI/CD Pipeline: Automating deployment workflows
- Advanced Monitoring: Setting up focused alerts and additional metrics
- GitOps Adoption: Moving toward a declarative GitOps approach with ArgoCD or Flux
Conclusion Link to heading
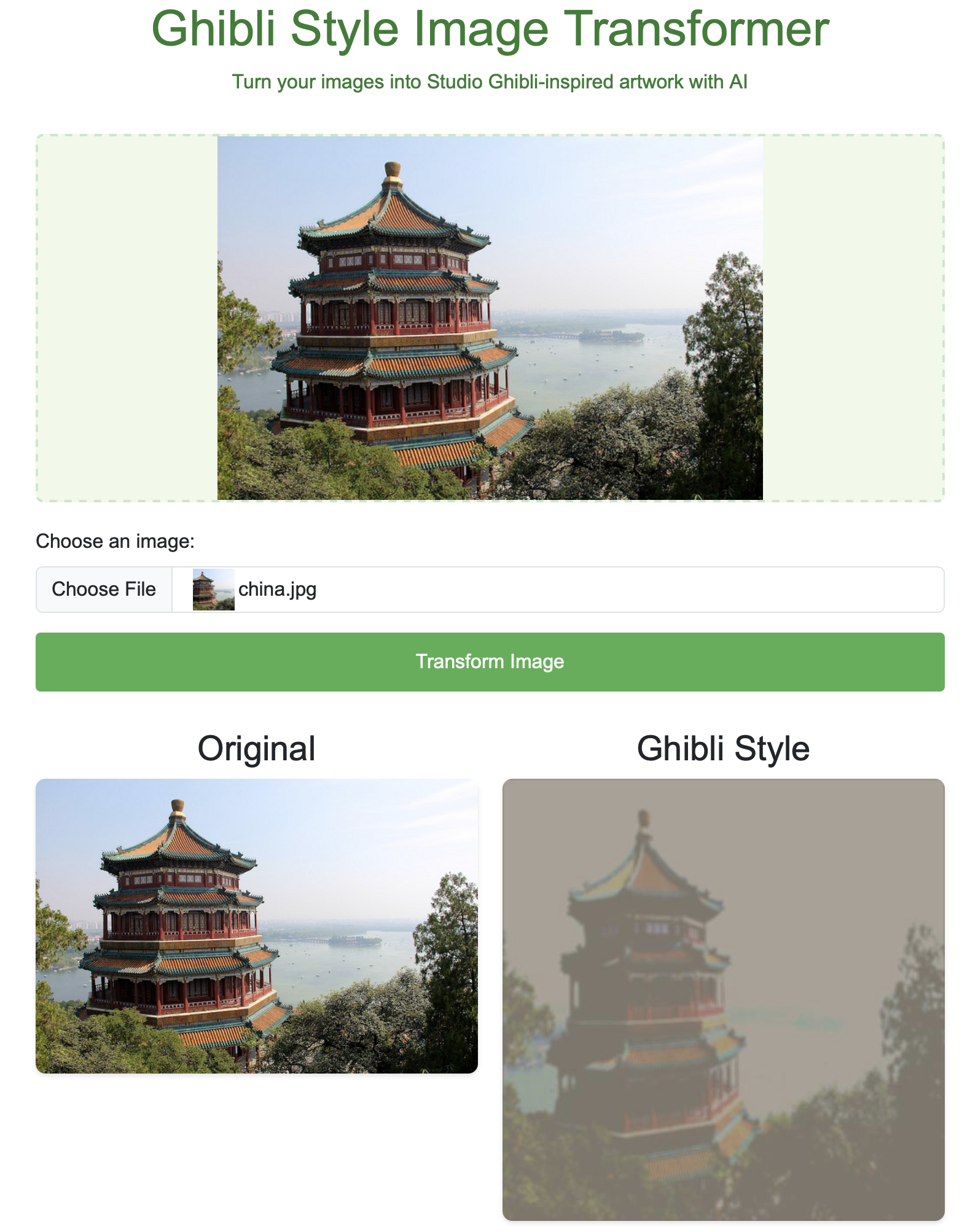
Had fun playing with AWS infra, Kubernetes, Terraform, Helm and Claude. Ghibli app wasn’t really doing a decent job of transformation and required more tuning which I wasn’t very interested in doing. ;-) I had it up at ghibli.doandlearn.app for sometime but becuase I don’t like being broke, I since turned down the infra to save cost. But the good thing is, everything is automated so I can bring it up if needed pretty quickly if needed.
Here is a sample:
 Link to heading
Link to heading
The complete code for this project is available in my selfhost_k8s repository.